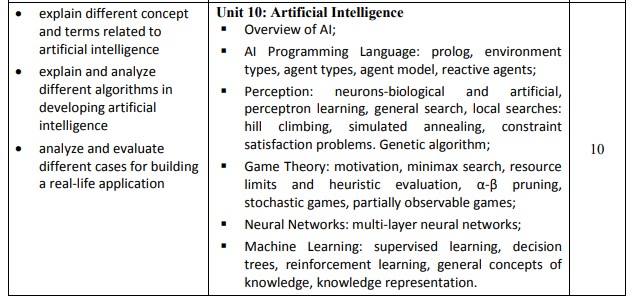
কৃত্রিম বুদ্ধিমত্তা বা আর্টিফিসিয়াল ইন্টিলিজেন্সের একটা শাখা বা সাবফিল্ড হলো মেশিন লার্নিং। এর মূল লক্ষ্য হলো প্রোগ্রামিং করে দেয়া ছাড়া একটি মেশিনকে তথ্য থেকে শেখা। অর্থাৎ এআই এর এলগোরিদমগুলো এমনভাবে ডেভেলপ করা যেন কোন একটি ডাটা দেখেই যেন সে প্যাটার্ণ এবং রিলেশনশিপ বুঝতে পারে এবং তার উপর ভিত্তি করে ফলাফল বা ভবিষ্যতবাণী (prediction) করতে পারে।
গেম থিয়োরি হলো এক প্রকার গাণিতিক হিসাব যা নির্ধারণ করে কোন এজেন্ট বা প্লেয়ার কোন সময়ে কি সিদ্ধান্ত নেয়। মাল্টি এজেন্ট সিস্টেমে এটি খুবই গুরুত্বপূর্ণ। গেম প্লেয়িং এআই সিস্টেমে গেম থিয়োরির মাধ্যমে বিশ্বের অনেক নামকরা গেমারদের এআই এর মাধ্যমে হারানো সম্ভব হয়েছে।
এটা যে শুধুমাত্র গেম খেলার সময় ব্যবহার করা হয় তেমনটা না। কমপ্লেক্স ডিসিশন মেকিং এর ক্ষেত্রেও এর ব্যবহার রয়েছে।
মিনিম্যাক্স সার্চ (Minimax Search)
টু প্লেয়ার গেম বা দুইজন খেলা যায় এমন গেমের সবগুলো সম্ভাব্য ধাপ নির্ধারণ করে আউটপুট বের করার মাধ্যমের নাম হলো মিনিম্যাক্স সার্চ। এটি একটি বহুল প্রচলিত এআই এলগোরিদম। যদি কোন একটি গেম যা দুইজন মিলে খেলা যায়, এমন গেমে এজেন্ট কি কি পথে আগাতে পারে সেটা মিনিম্যাক্স সার্চের মাধ্যমে সেটা সহজেই সিমুলেট করা যায়। এক্ষেত্রে শুরুতে মিনিম্যাক্স সার্চ এজেন্ট এর সব থেকে বেস্ট মুভ ধরে আগাতে থাকে। দাবা, টিক ট্যাক টো বা চেকারস গেমে এই সার্চ ব্যবহার করা হয় তবে আরও জটিল ধরণের গেম হলে এর কাজ করতে সময়ের প্রয়োজন হয়।
রিসোর্স লিমিটস Resource Limits and Heuristic Evaluation
একটি এআই সার্চ এলগোরিদমের কর্মদক্ষতা বাড়ানো জন্য রিসোর্স লিমিট এবং হিউরিসটিক ইভ্যালুয়েশন খুবই গুরুত্বপূর্ণ| প্রথমেই রিসোর্স লিমিটের কথায় আসি| রিসোর্স বলতে এখানে বোঝানো হচ্ছে একটি সিস্টেমের রিসোর্স যেমন: সময়, মেমরি| গেম ডেভেলপমেন্টের কথা যদি ধরা হয় তাহলে নিশ্চিত করতে হবে সার্চ এলগোরিদম যেন একটি নির্দিষ্ট সময়ের মধ্যে তার কাজ করতে পারে (চাল চালতে পারে বা মুভ করতে পারে) এবং এটি করতে গিয়ে সে যেন সব রিসোর্স ব্যবহার না করে ফেলে | কারণ এমনটি হলে সিস্টেম স্লো হয়ে যেতে পারে. উদাহরণ: দাবা অথবা তাস খেলার সময় যদি সিস্টেম স্লো হয়ে যায় তবে সেটি যথাযোগ্য হবে না।
হিউরিস্টিক ইভ্যালুয়েশন হলো ধরা যাক একটি দাবা খেলায় একজন মানুষ এআই এর সাথে খেলছে। তো প্রথম বা যে কোন অবস্থায় চাল যদি মানুষ চালে তার পরের চালটা দিতে হবে এআই কে। এক্ষেত্রে অনেকগুলো সম্ভাব্য মুভ থাকতে পারে যেটা এআই দিতে পারে। সার্চ এলগোরিদমটা এমনভাবে তৈরি করতে হবে যেন সম্ভাব্য কোনটা করলে সব থেকে ভালো হবে এটা বোঝার জন্য যেন সবগুলো সম্ভাব্য আউটকাম সিমুলেট না করা লাগে। কিসের পরিবর্তে কোনটা করলে ভালো হবে সেটা যেন সহজেই এলগোরিদম বুঝতে পারে। উদাহরণ: গেম প্রতিদ্বন্দিতাপূর্ণ না হলে সেটা খেলে মজা নেই।
আলফা বিটা প্রুনিং (A-B Pruning)
AB Pruning বা আলফা বিটা প্রুনিং হলো একটা সার্চ এলগোরিদম যা এআই এর মিনিম্যাক্স এলগোরিদমের কর্মদক্ষতা (Efficiency) বৃদ্ধি করে। এর কাজ হলো মিনিম্যাক্স এলগোরিদম থেকে যে সকল সম্ভাব্য আউটকাম পাওয়া যায় তার থেকে যেগুলোর সম্ভাবনা কম সেগুলো বাদ দিয়ে দেয়া। যেমন কোন একটি আউটকাম পর্যবেক্ষণ করার পর যদি পরবর্তী সম্ভাব্য আউটকাম পর্যবেক্ষণের শুরুতে বোঝা যায় যে, এটির থেকে এর আগেরটা ভালো ছিলো তাহলে আর সে ওইটার ভিতরে যাবে না। এতে করে সময় ও মেমরি অপচয় কম হয়। তবে এটা ব্যবহারে সমস্যাও আছে। গেম ট্রি যদি asymmetrical না হয় অথবা হিউরিস্টিক ইভ্যালুয়েশন ফাংশন যদি সঠিক না হয় তবে সে সঠিক ফলাফল দিতে পারে না।
স্টোকাস্টিক গেম (Stochastic Games)
Stochastic Games বলতে সেই সকল গেমকে বোঝায় যার ফলাফল শুধুমাত্র খেলোয়াড়ের উপর নির্ভরশীল না। সময় এবং সুযোগের উপরও নির্ভর করে। যেমন, একটা ডাইস রোল করলে অথবা ডেক থেকে একটা তাস তুললে সেটা কি হবে এটা কিন্তু বের করা বা এটার প্রেক্ষিতে কি হতে পারে সেটা বের করাও কঠিন। এই ধরণের খেলায় উদ্দেশ্য এবং স্ট্র্যাটেজি যখন তখন পরিবর্তন হতে পারে। তবে এটা যে শুধুমাত্র গেমের ক্ষেত্রে ব্যবহার হয় তা না। ফিন্যান্স, হেলথকেয়ার এবং ট্রাফিক ম্যানেজমেন্টেও এই পদ্ধতি ব্যবহার হয়। একে Partially Observable গেমও বলা হয়।
মাল্টি লেয়ার নিউরাল নেটওয়ার্ক হলো এক প্রকার আর্টিফিসিয়াল নিউরাল নেটওয়ার্ক যা গঠিত হয় বিভিন্ন লেয়ার বা স্তরে সংযুক্ত নোড অথবা নিউরন দিয়ে। প্রতিটি লেয়ারে ডাটা প্রোসেস এবং ট্রান্সফর্ম করা হয়। আউটকাম না আসা পর্যন্ত এক লেয়ার থেকে অন্য লেয়ারে ডাটা পাস করা হয়। এই নেটওয়ার্কের প্রথম লেয়ারকে বলা হয় ইনপুট লেয়ার। এর কাজ হলো ইনপুট নেয়া। ইনপুট লেয়ার থেকে ডাটা এক অথবা একাধিক হিডেন লেয়ারে প্রেরণ করা হয় সেটিকে প্রোসেস এবং ক্যালকুলেট করার জন্য। এর সর্বশেষ লেয়ারকে বলা হয় আউটপুট লেয়ার যেখানে আউটপুট দেয়া হয়। ইমেজ রিকগনিশন, ল্যাঙ্গুয়েজ প্রোসেসিং এর ক্ষেত্রে এটি ব্যবহার করা হয়।
সুপারভাইজড লার্নিং (Supervised Learning)
সুপারভাইজড লার্নিং হলো এক প্রকার মেশিন লার্নিং এলগোরিদম যেখানে একটি মডেল কোন একটি নির্দিষ্ট ডাটাসেটের মাধ্যমে ইনপুট-আউটপুট ম্যাপিং করে। সুপারভাইজড লার্নিং এর কাজ হলো মডেলকে এমন স্টেটে বা অবস্থানে নিয়ে যাওয়া যাতে করে সে পূর্বে অভিজ্ঞতালব্ধ ঘটনা ছাড়াও যেন ইনপুট-আউটপুট ম্যাপ করতে পারে। সুপারভাইজড লার্নিং দুই প্রকার। রিগ্রেশন এবং ক্লাসিফিকেশন।
ডিসিশন ট্রি (Decision Trees)
Decision Trees হলো এক প্রকার মেশিন লার্নিং এলগোরিদম যা সুপারভাইডজ লার্নিং এর উপর কাজ করে। এটি একাধারে ক্লাসিফিকেশন এবং রিগ্রেশন টাস্কে ব্যবহার করা যায়। ট্রি এর সব থেকে উপরের অংশকে বলা হয় রুট যেখানে ডাটাসেট থাকে। ইনপুটের উপর ভিত্তি করে রুট নোডকে একাধিক ভাগে ভাগ করা হয়। ভাগ করা এসব নোডকে বলা হয় চাইল্ড নোড। এক একটি চাইল্ড নোডে এক একটি কন্ডিশন সমাধান করা হয়। যত সময় পর্যন্ত সকল সমস্যা সমাধান না করা হয় ততক্ষণ পর্যন্ত প্রতিটি চাইল্ড নোডে রিকারসিভ প্রোসেস চালানো হয়। রুট থেকে লিফ নোড পর্যন্ত সম্ভাব্য অপারেশন চালিয়ে তারপর আউটপুট নির্ণয় করা হয়।
রিইনফোর্সমেন্ট লার্নিং (Reinforcement Learning)
রিইনফোর্সমেন্ট লার্নিং হলো এক ধরণের কৃত্রিম বুদ্ধিমত্তা বা এআই যা তার নিজের অভিজ্ঞতা থেকে শেখে। একটি এজেন্ট তার পারিপার্শ্বিক অবস্থানে বিভিন্ন টাস্ক বা কাজ করে তার ফিডব্যাকের মাধ্যমে শেখে যে কাজটি সঠিক বা ভুল অথবা কতটা সঠিক। এই কাজটি আরও কি কি করলে ভালো আউটপুট দেয়া যায় সেটাও সে শেখে। উদাহরণ: ভিডিও গেম, রোবোটিকস।
নলেজ কনসেপ্ট (General Concepts of Knowledge)
Artificial Intelligence বা কৃত্রিম বুদ্ধিমত্তায় Knowledge বলতে সেটিকে বোঝায় যেটা ব্যবহার করে একটি এজেন্ট বিভিন্ন সমস্যার সমাধান করে অথবা সিদ্ধান্ত গ্রহণ করে। এআই এর জন্য একটি সমস্যার ধরণ বুঝতে বা সেটি সঠিক উপায়ে সমাধান করতে Knowledge প্রয়োজন। বিভিন্ন প্রকার Knowledge:
Explicit knowledge
Tacit knowledge
Domain knowledge
Procedural knowledge
নলেজ রিপ্রেজেন্টেশন (Knowledge Representation)
Knowledge representation হলো এআই এর এমন একটি উপাদান যা দিয়ে ফরমাল মেথডকে এমনভাবে ডিজাইন ও ডেভেলপ করা হয় যেন Knowledge কে পরিবর্তন বা পরিবর্ধন ঘটিয়ে জটিল বা কমপ্লেক্স সমস্যা সমাধান করা যায়। নলেজ রিপ্রেজেন্টেশন অবস্থা ও সময়ের ভেদে পরিবর্তন হতে পারে। বিভিন্ন প্রকার Knowledge representation:
Logic-based approaches (লজিকের উপর ভিত্তি করে)
Semantic network-based approaches (গ্রাফিকাল রিপ্রেজেন্টশন বা কনসেপ্টের মাধ্যমে)





 | শিক্ষক নিবন্ধন লিখিত | পর্ব ১০.১")




